一文彻底搞懂http
前文
http,我们熟悉又陌生的名词;熟悉是因为我们天天都有在使用它,又因很多前端同学工作几年,甚至以为http请求只有get和post两种请求的方法,足以证明http的陌生程度.我以前对http也是没有引起重视的,只是有简单的了解一些,直到最近几次面试都问到这个😭,我才意识到这方面知识的欠缺.
没关系,有心开始就不算晚,今天就让我们彻底搞懂这个玩意,去和面试官谈笑风声🤔.
先来个经典的面试题吧,从键入url到视图呈现发生了什么?
不少面试官一上来就问这玩意😀
我们输入baidu.com回车,浏览器会首先帮我们补全url变成https://www.baidu.com/,然后检查本地缓存,如果资源需要从服务器获取,那么就需要域名解析了,这个时候就会去最近(最近是说,如果你的本机或者路由器有对应的映射关系,那么就不需要去网络查询,最简单的情况是你直接改了hosts文件)的dns服务器获取url对应的ip地址,好,找到你了!开始交♂流吧!交流就需要桥梁啊,这个时候就该tcp链接出马了,只见客户端和服务器之间架起了一座桥,是的他们建立了tcp链接,建立结束后,客户端就可以发送请求啦,,服务器处理完对应请求然后返回给客户端,好的交流结束,关闭tcp链接.客户端收到这些资源就该干活了,我们的客户端是浏览器,浏览器开始解析这些资源,通过html解析成dom树,通过css解析为css规则树,最后dom树和css规则树合并为渲染树,js的执行和加载都会影响上边两者的解析和渲染(这也是为啥我们一般放到底部的原因),浏览器会根据这颗渲染树计算每个节点的位置大小等信息,然后在页面绘制出这棵树,视图就呈现啦~
http正式登场
可以看到上边我们交换数据的地方是一笔带过的🤫,其实中间有很多小细节,让我为你一一道来
首先我们要说的是网络分层模型
经典的分层模型(括号内是代表事物):
- 物理层(网线,光缆,网卡硬件...)
- 数据链路层(网卡软体(驱动)...)
- 网络层(路由器...)
- 传输层(tcp,udp...)
- 应用层(http,samba,ftp...)
我们的网络是很多东西组成的,举个例子,如果你的机器没有网卡,你能上网吗?很明显不能,因为它也属于网络模型中不可或缺的部分,网卡在这里担任的就是数据链路层(其实也可以摆在物理层)
我们不需要关注低三层:物理层,数据链路层,网络层;因为传输层会屏蔽掉下层的通信细节,嘿嘿嘿,正是我们想要的形状;我们的http是建立在tcp之上的,而且也屏蔽了传输层的细节,嘿嘿嘿
他们之间是有一个封包和拆包的关系的,这头包装那头拆最终每层都能见到属于自己的东西,可以见下图: 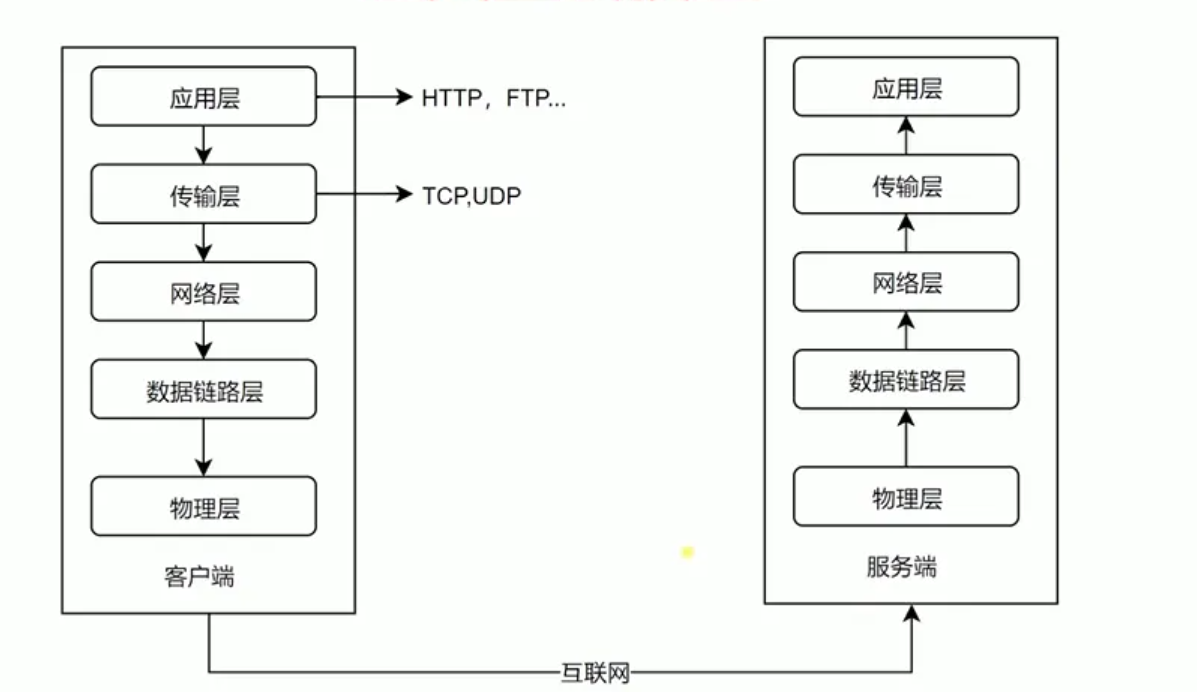
http版本发展历史
来观望一下http发展历史
0.9
初版是很简陋的
- 他只有一个请求方式
get - 没有数据的描述信息(header)
- 服务器发送完毕,直接关闭
tcp链接,无法实现链接的复用
1.0
- 增加了新的请求方式(
post,put...) - 增加了状态码(status code)和数据描述信息(header)
- 增加了多字符集支持,缓存等
1.1
- 持久化链接,实现链接的复用,不用频繁创建链接(服务端可以通过
Connection头来控制) - pipeline
- 增加host和一些其他命令
2.0(未来的主流)
- 数据都以二进制传输,在此之前数据都是字符串形式
- 对pipeline的优化,同一链接里的多个请求不再需要按照顺序
- 头部信息的压缩以及服务端推送(server push)等
http2的诞生解决了长链接必须按照顺序发送请求的问题,以帧为单位发送数据可以不论先后,服务器收到后会根据帧信息合成完整的数据.这里值得提一下服务端推送,以往我们在页面里的css和js等需要通过解析html之后才能发起请求的资源,可以通过服务端推送直接推送给客户端,这些资源不再需要等待html的解析之后发起的请求,相当于和html是并行加载的,哇,加载速度又提高了一丢丢
来了老弟!三次握手
经典的不灭之握😱~
- 第一握:客户端发送
SYN=1,Seq=X - 第二握:服务端收到后,发送
SYN=1,ACK=x+1,Seq=Y - 第三握:客户端收到确认(ACK===X+1)后,发送
ACK=Y+1,Seq=Z,服务端确认(ACK===Y+1)后就开始等数据
说一下为什么需要三次握手吧,它主要解决一件事情:就是为了防止错误的数据包被发送到服务端,产生错误
流程图如下: 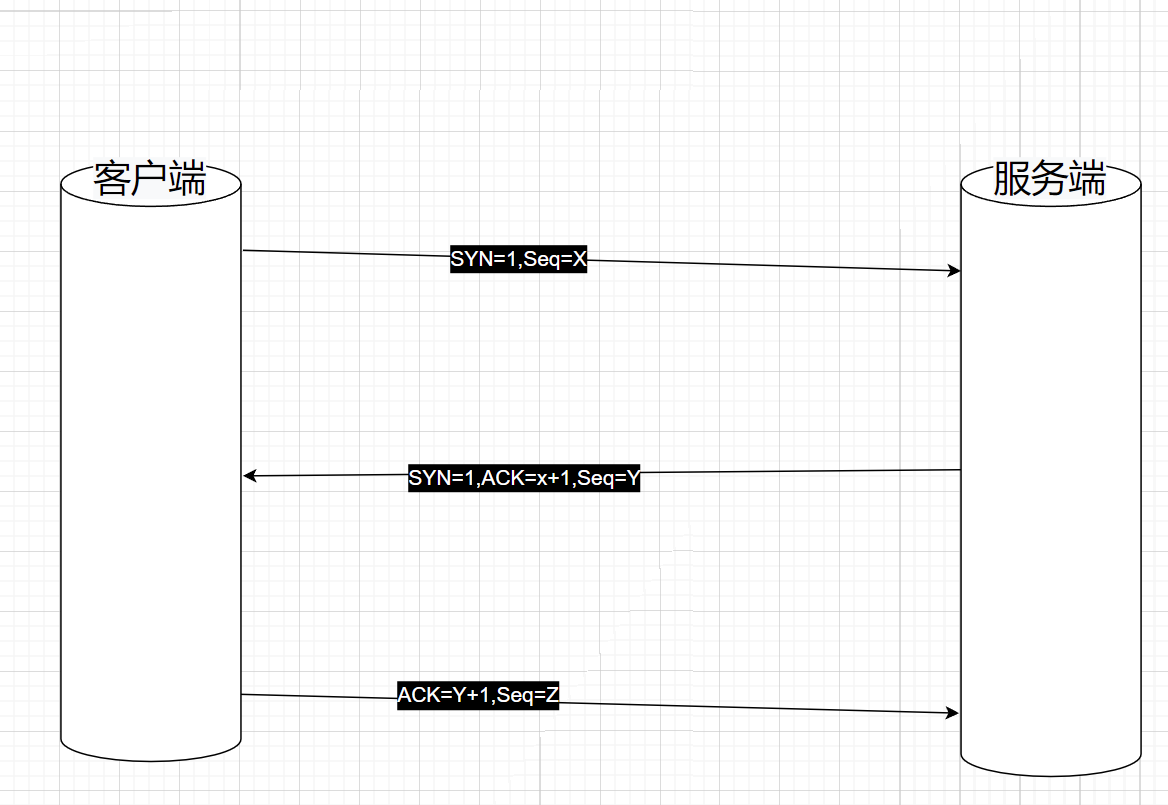
报文格式
每个报文第一行都被称为起始行(起始行各部分用空格隔开),然后从第二行开始就属于头部,最下边是主体部分,主体和头部之间会空起一行分割
请求报文
请求方法 资源定位符 协议版本
GET /baidu.com HTTP/1.1
一一一一一一一一一一一一一一一一一一一一
请求头
Accept:text/*
一一一一一一一一一一一一一一一一一一一一
请求主体(get post其实都可以有请求体,千万别以为get没有请求体)
响应报文
协议版本 状态码 状态码描述
HTTP/1.1 200 OK
一一一一一一一一一一一一一一一一一一一一
响应头
Content-type:text/plain
一一一一一一一一一一一一一一一一一一一一
响应主体
HI,我是小度小度
这里稍微说一下状态码各区间的含义
| 区间 | 含义 |
|---|---|
| 100~199 | 还需要做一些额外的操作,这个请求才会返回给你 |
| 200~299 | 这个请求能处理,并能成功返回 |
| 300~399 | 重定向 |
| 400~499 | 发送的请求有问题 |
| 500~599 | 服务器端出现问题 |
这里说一下301/302状态码,服务端只需要在头部生命"Location",就会去往声明的地址,这两者缺一不可;301是指永久重定向,下次浏览器就不用问服务器了直接重定向,所以要慎重使用,因为初次请求之后控制权就不在服务端了,302是临时的,每次都要和服务器交互获取跳转地址
浏览器的同源策略
为什么会存在跨域呢?一句话,为了防止恶意网页可以获取其他网站的本地数据。
同源策略的影响:
- 不能获取dom结构
- 不能获取cookie/indexdb/Storage
- 不能正常获取非同源ajax响应数据
注意,这是浏览器的特色行为,其实在跨域ajax整个发生过程中,请求达到了服务端,服务端也返回了数据,但是浏览器意识到这是跨域行为,然后给拦截了.
怎么解决ajax跨域呢?目前主流的方式:
- JSONP(其实非主流)
- proxy代理服务器
- 设置响应头的跨域范围,"Access-Control-Allow-Origin": "*"
CORS预请求(也叫预跨域请求,来自某次面试的丢人痛击)
就上面跨域范围设置后,还值得一说的是,其实也并非所有请求方式和请求头可以正常放行,其实这样设置之后也只是get,post,head请求方法可以通行,也是浏览器默认允许的跨域请求方式,其余方法是不允许跨域的,同样的情况请求头也有一些限制;怎么解决这种情况呢,那就是cors预请求,浏览器会先向服务器发起预请求来查验哪些头部和方法可以跨域,然后才会发送跨域请求;这个操作需要服务器端配置好相应的允许名单(Access-Control-Allow-Methods以及Access-Control-Allow-Headrs);这个问题也让我想起了某一次面试,面试官问我,有没有遇到过浏览器发请求的时候会发送两次请求,第一次是空的(你会看到请求的方法是:options),第二次才会真正发起请求,我心想这是啥玩意?还有这种情况?果然,无知最可怕啊😂
与上边配套的还有一个Access-Control-Max-Age,使用它可以让浏览器在预请求之后,在一定的时间内不需要再次发起预请求,可以直接发起跨域请求
http缓存(Cache-Control)
又是一个经常问到的点,我们可以利用它来减少请求数,提高性能,先来看一些它的主要概念
什么是可缓存性?
可缓存性是指可以在网络哪一个环节进行该资源的缓存,通常在header里指明就行,但是headerd通常只是一种声明,不是强制性的,需要客户端去遵守这些规则,这个一定要注意
- public 可以在任何节点进行缓存
- private 只可以在发起请求的客户端上进行缓存
- no-cache 可以缓存,但是必须和服务器验证是否可以使用缓存
- no-store 任何节点都不能进行缓存,永远进行网络请求
- no-transform 禁止节点对资源进行更改,比如压缩等
什么是缓存期限?
是指缓存的有效期,超过这个有效期,缓存会被标记为失效,再次请求需要从网络上获取
- max-age
- s-max-age 只有在代理服务器生效,比max-age优先级高
- max-stale 这个期限内不受缓存有效期的影响(浏览器使用不到)
验证规则(协商缓存)
- must-revalidate 缓存到期后,必须进行验证才能使用
- proxy-revalidate 同上,但是用在缓存服务器
这里简单说一下验证的方式,通常有两种:一种是对比修改的时间(last-modified),一种是对比文件的签名(内容的更改,etag)
所谓的强缓存和协商缓存
强缓存其实就是指定缓存期限来实现,协商缓存就是采用验证规则来实现,如果两者都用上了,那么强缓存是优先级更高的
cookie以及session
服务端响应头部设置Set-Cookie后,这玩意就会出现在请求头中
它的一些属性:
- max-age 设置失效时间,经过多少时间失效
- expires 设置失效时间,到某个时间点失效
- Secure 表示只有在请求时https时,cookie才会被发送
- HttpOnly 只能通过服务端读取操作,客户端是无法读取的
- domain 使用范围
session其实并不依赖于cookie,它只是服务端用来确定空间的一种依据,不过通常在web中,多用cookie来实现
数据(类型)协商
就是客户端通过头信息告诉服务端我想拿到一个什么样的数据,服务端在收到后,通过处理返回响应的数据,但是不是强制性,"你要苹果,我给梨,就是玩~"
请求端
- Accept 类型
- Accept-Encoding 编码,压缩(gzip)
- Accept-Language 语言
- User-Agent UA客户端标识
服务端
- Content-Type 类型
- Content-Encoding 编码,压缩(gzip)
- Content-Language 语言
https
解决了http一个明显的问题:安全,安全,还是TMD安全.
众所周知,http整个传输过程都是明文的,这样的结果就是传输过程中每一个节点都可以看到传输的是什么东西,甚至可以对其加以篡改.https就在这样的情况下诞生了,很合理.那为什么说https就很安全呢,因为它在传输过程中是加密的,双端使用密钥进行加密解密,在传输过程是无法被破译的.
握手过程
ssl的握手过程发生在tcp三次握手之后,所以性能肯定是比http拉的,别人三次握手之后就干活了,我们还需要生成密钥
- 客户端发起握手,发送自己生成的随机数并附带自身支持的加密方式(加密套件)
- 服务端收到后同样返回一个自己生成的随机数,并发送证书(里边包含公钥)
- 客户端收到后通过证书加密生成一个预主私钥(其实就是新产生的一个随机数,如果面试官问你一共产生了几次随机数,答案是三次)
- 服务收到后使用私钥进行解密,得到预主私钥
- 双端各自在本地计算出对称加密所需要的密钥,由于这个是本地计算的,没有经历过网络传输,所以是安全的,之后双方就可以愉快的进行加密传输了
整个过程如图下图: 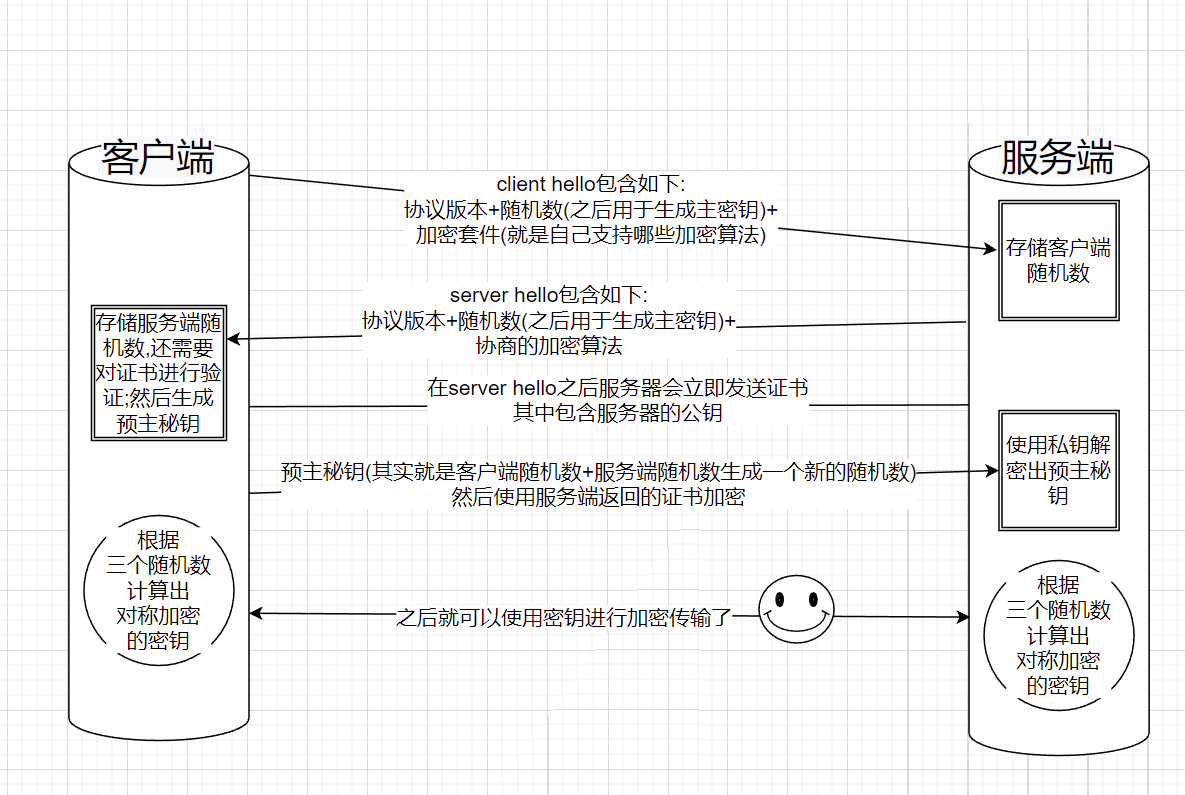
你或许会疑惑,这样真的安全吗?
你或许会想到,虽然所需要的密钥是本地计算的,我们无法获取,但是它的三个随机是经过了网络传输的,我们在中间劫持到这三个随机数,然后在使用和他们同样的算法岂不是可以生成一样的密钥?wow~我们可真是个大聪明!盲星你发现了华子~其实不然,因为你在传输第三个随机数的时候使用了服务端的公钥进行加密,但是破译却需要服务端的私钥,如果私钥没拿到,那么你根本无法得到第三个随机数,酱紫懂了吧;这也是ssl的一大特点,如果私钥泄露,那将毫无秘密可言~
又衍生一个问题,那抓包软件是咋获取到我的请求的,抓包软件可以解析你的请求是因为你信任了它的证书,它在中间先解密再用自己的密钥加密,双端是可以没有任何感知的
拓展问题
相关的拓展问题
TCP和UDP的区别
这个也很多地方问到,但是都是一些概念性的东西,我们需要做的是去了解一下他们的优缺点和区别,知道使用场景即可
TCP的特点
- 面向链接:在两端传输数据之前需要建立链接
- 仅支持单播传输:仅支持一对一传输,也就是点对点
- 面向字节流:字节流传输
- 可靠传输:依靠TCP的段编号和确认号来判断是否数据丢包或者错误数据
- 拥有阻塞控制:动态的调整速率和数量
UDP的特点
- 面向无链接:无需握手,想发就发,想收就收
- 有单播多播广播:支持一对多,多对多,多对一等传输方式
- 面向报文:数据都是通过一个一个报文源源不断传输
- 不可靠:由于没有建立链接,数据不可靠,丢包等无法判断
- 头部信息小:头部开销很小
对比
| TCP | UDP | |
|---|---|---|
| 面向链接 | YES | NO |
| 可靠 | YES | NO |
| 传播方式 | 字节流 | 报文 |
| 传播对象 | 一对一 | 一对一,一对多,多对一,多对多 |
| 头部开销 | 20字节~60字节 | 8字节 |
| 使用场景 | 视频,直播,电话等 | 文件传输等 |
对称加密和非对称加密的区别
对称加密:双方约定好一个密钥,双方加密解密都使用这个密钥来完成 公式:
- 源文件+密钥=加密文件
- 加密文件-密钥=源文件
非对称加密:一方持有公钥,一方持有私钥,通过公钥加密的数据通过私钥来解密 公式:
- 源文件+公钥=加密文件
- 加密文件-私钥=源文件
| 对称加密 | 非对称加密 | |
|---|---|---|
| 安全 | 只要一方丢失密钥,GG | 只要私钥不丢失即可 |
| 速度 | 由于算法,对称加密更快 | 算法相对复杂,慢一些 |
终于结束
goodbye👋